 İnce Satırlar
İnce Satırlar Liste Modu
Liste Modu Döşeme Modu
Döşeme Modu Sade Döşeme Modu
Sade Döşeme Modu Blog Modu
Blog Modu Hibrit Modu
Hibrit Modu

Nvidia da chiplet trenine biniyor
Güvenilir donanım sızıntısı Kopite7kimi’nin son söylentilerine göre iki şey ön plana çıkıyor: Birincisi, Nvidia’nın günümüz veri merkezi segmenti için ilk chiplet tasarımını kullanması bekleniyor. Kısaca özetlemek gerekirse, Nvidia Blackwell GPU'larının başlangıçta chiplet rotasına giren ilk aile olması bekleniyordu, ta ki söylentiler şirketin buna yanaşmadığını ve daha standart bir monolitik tasarım kullanacağını bildirene kadar.
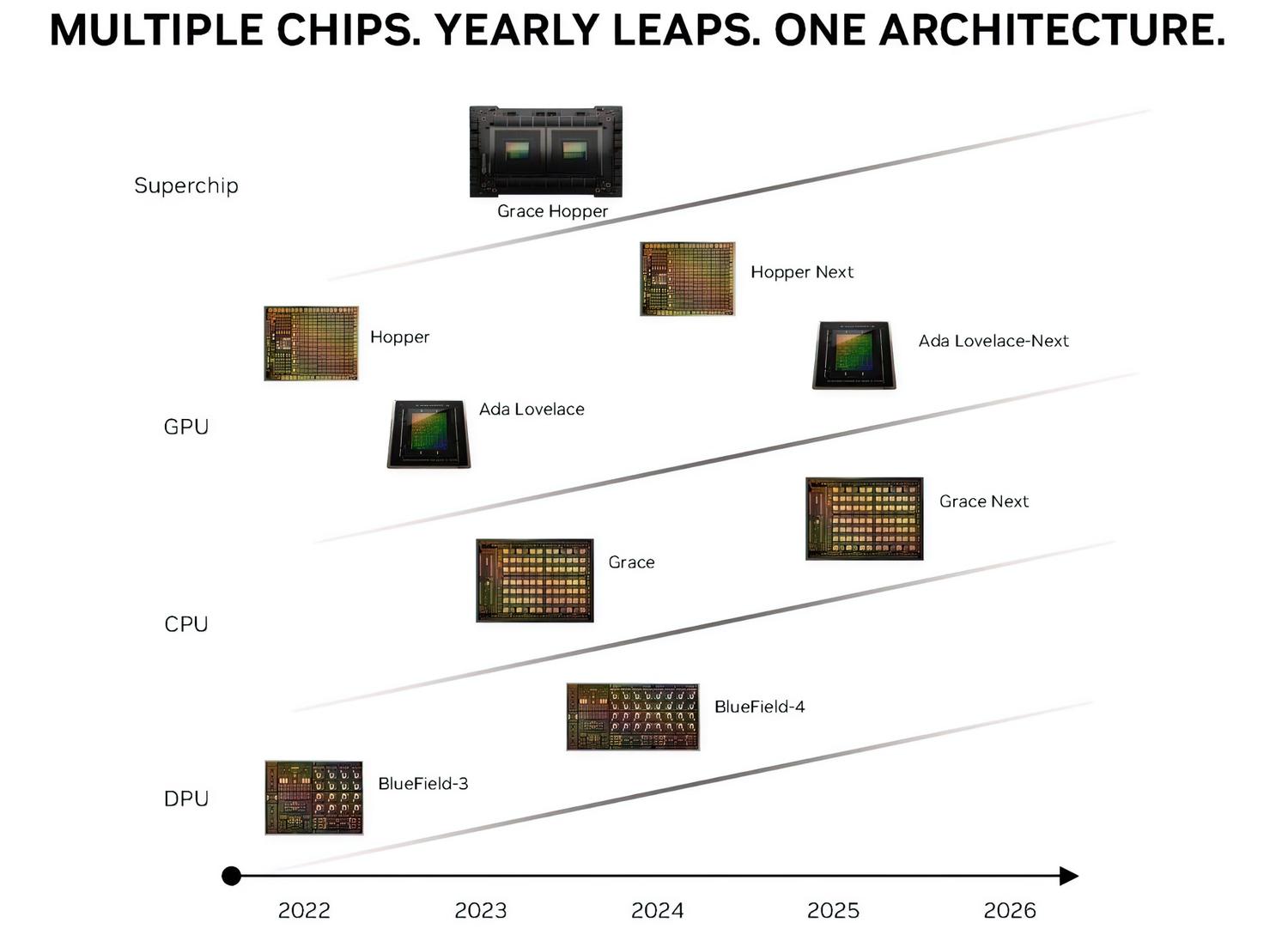
Nvidia şimdiye kadar Hopper ve Ada Lovelace GPU'ları ile sektörün chiplet kullanmadan da ilerleyebileceğini kanıtladı ve her ikisi de watt başına en iyi performansı ve şirketin şimdiye kadar gördüğü en yüksek marjları sunma konusunda başarılı oldu. Ancak görünüşe göre ilerleyen zamanlarda bu durum değişecek ve Blackwell'den başlayarak chiplet trenine binilmiş olunacak. Blackwell GPU'larının veri merkezi ve yapay zeka segmenti için 2024 yılında piyasaya sürülmesi planlanıyor.
Chiplet tasarımını kullanmak için uygun üretim tiplerini (TSMC 3nm, Samsung 4nm gibi) bir araya getirmek gerekiyor. Dolayısıyla maliyet etkin bir süreç olsa da tedarik konusunda sıkıntı yaşanmaması kritik öneme sahip. TSMC’nin öncü paketleme teknolojisi CoWoS, AMD ve Nvidia’nın kullanabildiği kilit paketleme teknolojilerinden biri ancak her iki şirket de TSMC'nin en iyi teknolojisine erişmek için savaşıyor gibi görünüyor. Bu mücadele genellikle kimin daha fazla para teklif edebileceğine bağlı. Dolayısıyla koz, Nvidia’da.
Ayrıca, Nvidia’nın kullanmak istediği yonga seti tabanlı entegrasyon seviyesine bağlı olarak tedarik edilmesi gereken başka önemli bileşenler de var. Hem AMD hem de Intel, tek bir yonga paketi üzerinde birkaç IP'yi entegre eden bazı gelişmiş yonga seti paketleri yapıyor, bu nedenle Nvidia’nın Blackwell'deki birinci nesil yonga seti mimarisi için tasarımının ne kadar gelişmiş olduğunu görmek ilginç olacak. Öne çıkan ikinci şey ise Blackwell GPU'larının mimari yapısıyla ilgili. Blackwell GPU'larındaki grafik ve doku kümeleri gibi birimlerin sayısının Hopper'dan çok fazla değişmediği, ancak iç birim yapısının (SM/CUDA/Cache/NVLINK/Tensor/RT) önemli ölçüde değişeceği belirtiliyor. Dolayısıyla performans kazanımının bu temellere yayılması hedefleniyor.
Bu haberi, mobil uygulamamızı kullanarak indirip,istediğiniz zaman (çevrim dışı bile) okuyabilirsiniz:










ChatGPT doğru dinin İslam olduğunu söylüyor zaten.
Joe bidenden iyi yürüyo